
The Multi-Agent Reality (2026): Why is the era of single chatbots over?

Build a multi-agent dev squad with LangGraph and PydanticAI. Learn 7 proven steps to boost autonomy, cut bugs, and ship faster in 2026 for real-world teams now
And how to build a production-grade multi-agent dev squad using LangGraph + PydanticAI
We are not in 2023 anymore. The “chatbot phase” – where engineers showed beautiful demos of LLMs preparing emails or summarizing documents – is now dead. In 2026, interactive intelligence has transformed into something even more powerful and demanding: digital workers – autonomous, specialized agents who think, act, and function as a team, not as individual responders.
This is not marketing fluff. The industry asks “What can an LLM say?” By asking “What can AI do autonomously and reliably?” has shifted to – and right now, practical systems only work when they are architected as multi-agent systems (MAS), not monolithic super-prompts.
In this post, we’ll break down the following:
- Why Single Agents Fall Apart Under Complexity
- The Real Roles Behind the Dev Squad
- Why Langgrah and PydanticAI Are Leading the 2026 Stack
- How to Build a Production MAS Workflow
- Code Snippets You Can Use Today
- Real Caveats, Pitfalls, and Trade-Offs – Not Just Hype
- A Solid FAQ with Accurate, Sourced Answers
Table of Contents
1. Why Single Agents Always Hit the Wall
Initially, everyone tried to turn every task into a single “super-agent.” One model. One giant prompt. Half a dozen tools. It seemed clever. In practice it quickly exploded:
Cognitive overload
Large language models are not CPUs – they are predictive text engines. Throwing too many responsibilities into a single prompt (planning, coding, reviewing, deploying, checking compliance), and behaviors deteriorate:
- Confusion increases
- Context is left out or misinterpreted
- Output becomes brittle and inconsistent
That’s not subjective – industry engineers saw exactly the same thing when trying end-to-end agent tasks. Simply cascading tools without a framework break down under real-world complexity.
No checkpoints, poor error handling
Training these systems to “just do it” leaves no recovery path when things go sideways. The review steps fold into the same logic context, so the agent continues to repeat errors rather than asking for help or signaling failure.
Non-modular scaling
When you need better security, deeper validation, or a different feature (e.g., security policy versus documents versus infra), you can’t just “add it to the prompt.” You need roles.
The conclusion is obvious but inescapable:
Single agents explode once you reach even moderate complexity – and that’s why the multi-agent paradigm is now the standard approach for production agent systems in 2026.
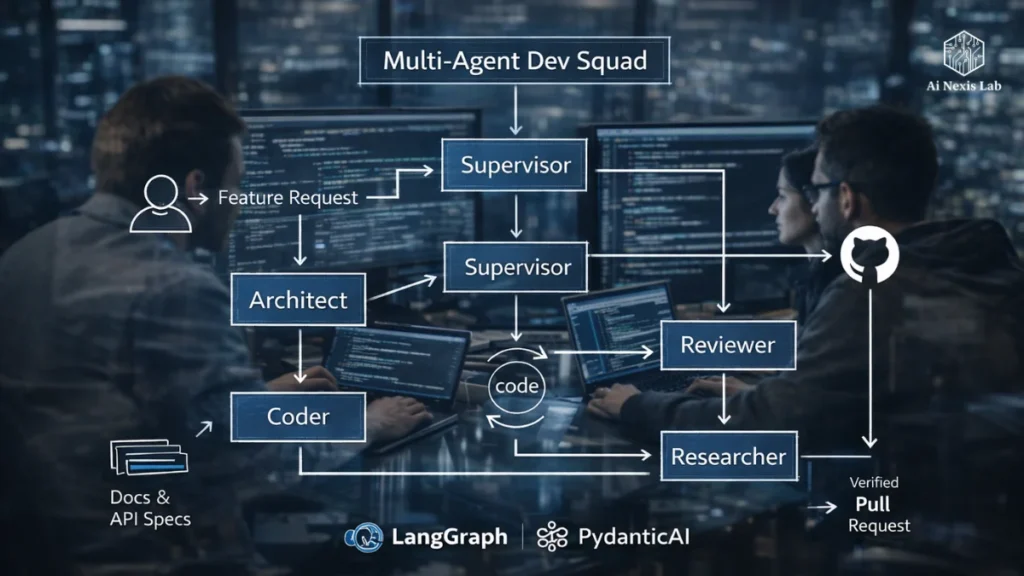
2. Multi-agent dev squads: specialized, not generalist
A modern MAS is not a bunch of ChatGPT copies talking to each other. It is a structured system where each agent has a distinct role – and a clear contract.
Think of it like a real engineering team:
| Role | Responsibility |
|---|---|
| Architect | Breaks down tickets into a plan + schema |
| Coder | Writes code to spec |
| Reviewer | Checks logic, style, security, performance |
| Researcher | Fetches docs, APIs, specs, external context |
| Supervisor | Routes work, enforces policies, coordinates hand-offs |
This mirrors human teams because digital problems at scale behave similarly to human problems: they have uncertainty, assumptions, and failure modes.
The sooner you treat your MAS as a squad with roles and responsibilities, the sooner it will stop feeling like a hack and start behaving like a system.
3. Why LangGraph + PydanticAI are a 2026 Power Duo
In 2026, two frameworks have emerged as the most realistic and production-ready foundations for MAS in the Python ecosystem:
LangGraph — for orchestration and state
Created by the LangChain team, LangGraph is designed to manage stateful workflows where agents can execute, interact, and loop back based on results. It models the workflow as a clear graph of agent states and transitions, not as a static chain of prompts.
This is important because:
- Workflows are not linear – you need branches, loops, approvals, and recovery paths.
- State matters – actual processes cannot be “forgotten” mid-stream.
- Observability is important – you want to find out what happened, when and why.
Langgraf does this out of the box, with hooks for human interruption and rerouting.
Simply put: it turns an abstract process into a state machine that you can debug, test, and reliably run.
PydanticAI – For Type Safety and Prediction
When orchestrating a language graph, PydanticAI enforces structured contracts between agents. Think of it as a software engineering layer that ensures:
- Each agent’s input and output are typed and validated
- If something goes wrong, you know exactly why
- You treat each agent’s results as data, not arbitrary text
PydanticAI treats agents with a clear schema, like Python classes – meaning your system behaves predictably, not probabilistically.
This drastically reduces one of the biggest pains in MAS: when two agents speak in ambiguous natural language, the downstream agent never knows whether the upstream result is valid or not.
In short:
Langgraph manages the flow, PydanticAI manages the contracts.
Together, they give you something close to classic software engineering – but with generative models as the execution engine.
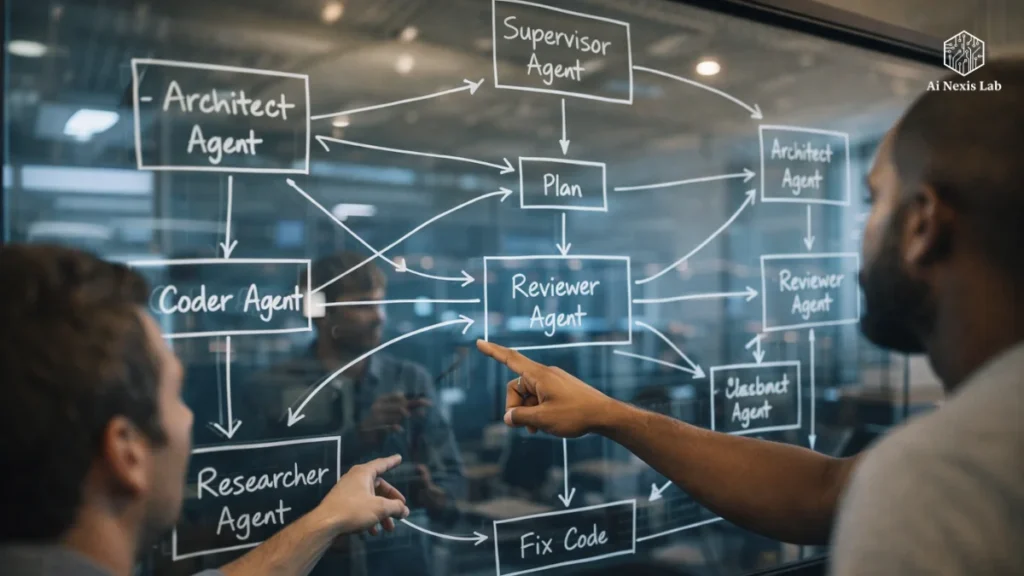
4. How Real Dev Squad Architecture Works
Let’s see how meaningful workflows are actually executed in MAS – from issue to verified PR.
Step 1: Ticket Ingestion (Supervisor)
A human or system supervisor enters a GitHub issue/engineering ticket into the agent.
This agent:
- Analyzes metadata (labels, priorities)
- Selects a squad or subgraph
- Defines execution context and schema
Step 2: Break down (architect)
The architect agent:
- Analyzes ticket text
- Maps it to engineering tasks
- Outputs a JSON schema describing the subtask
If the JSON schema does not match expectations, it triggers a schema failure instead of obfuscating the missing steps.
PydanticAI ensures that you get truly structured tasks, instead of paragraphs of text you have to manually parse.
Step 3: Code (Coder)
The Coder agent takes a structured task description and writes the code.
Instead of open-ended text attempts, he writes code that fits into a schema. If something doesn’t type-check, you handle the error programmatically.
Step 4: Review (Reviewer)
Reviewer agent:
- Runs static analysis
- Checks security rules
- Runs test scenarios
- Reports structured feedback
- Makes an acceptance/rejection decision
If rejected, LangGraph sends the workflow back to the coder with specific feedback.
Step 5: Final Output
Once the final standards are met:
- The supervisor closes the loop.
- Optionally opens the full history/log attached PR.
- Records metrics (task autonomy rate, latency, failure modes).
This is not “AI magic”. It is structured control flow + validation + auditability.
5. A working code snippet (Real Starter)
Here is the minimal pattern you can use to create your own squad.
Please note: This code is a concept, not a turn-key product. Before copying, make sure you understand how your LLM calls and environment profiles work.
from pydantic import BaseModel
from pydantic_ai import Agent as PydanticAgent
from langgraph import StateGraph, Node
# -----------------------------
# Schemas
# -----------------------------
class Plan(BaseModel):
tasks: list[str]
class CodeResult(BaseModel):
code: str
class ReviewResult(BaseModel):
approved: bool
issues: list[str]
# -----------------------------
# Define Agents
# -----------------------------
architect = PydanticAgent(
model="openai:gpt-5",
output_type=Plan,
instructions="Decompose feature request into tasks."
)
coder = PydanticAgent(
model="openai:gpt-5",
output_type=CodeResult,
instructions="Write code implementing tasks."
)
reviewer = PydanticAgent(
model="anthropic:claude-3.5",
output_type=ReviewResult,
instructions="Review code for correctness and security."
)
# -----------------------------
# LangGraph Workflow
# -----------------------------
graph = StateGraph()
graph.add_node("architect", Node(architect.run))
graph.add_node("coder", Node(coder.run))
graph.add_node("reviewer", Node(reviewer.run))
# Conditional routing: if review fails, go back to coder
graph.add_conditional_edges(
"reviewer",
lambda r: "coder" if not r.approved else None
)
# -----------------------------
# Run
# -----------------------------
result = graph.run(initial_input={"issue_text": "Add asset tagging feature"})
print(result)
This framework:
- Uses strict schemas
- Routes based on outcomes
- Integrates multiple models
- Avoids ambiguous natural language hand-offs
6. The 2026 Reality: What’s Really Ship-Ready
Before you get bogged down in abstractions, let’s be honest about where we are in 2026:
Enterprise adoption isn’t universal — but it is real
According to industry data, more than 57% of organizations with agents report product usage, and observability is the table stakes for anything serious.
That means companies with no monitoring, no test harnesses, and no recovery paths are not in production – they are in demo.
Multi-agent systems are common – not strange
Developers are increasingly creating MAS because complex tasks simply don’t fit into single loops. And thanks to frameworks like Langgraph and PydanticAI, product setup is possible without crazy investments.
Token costs and loops still sting
If you let agents trade messages uncontrollably, your token usage increases – and can quickly exceed value if it is not capped.
Guardrails are mandatory
MAS systems without policies lose data, make careless API calls, or produce unsafe artifacts. Guardrail agents (hard stops, human clearances) are now best practice.
Observability Frameworks Are Important
Systems like Langsmith, Logfire, and third-party tracing are not optional if you want enterprise-grade telemetry and debugging.
7. A Brutally Honest Reality Check
Let’s cut through the fluff:
You still need engineers.
These systems are not a substitute for decision-making, product thinking, or ownership. They reduce effort, do not replace authorship.
You will debug agent logic just like software logic.
This is not a simulation – it is a distributed, non-deterministic workflow that requires serious engineering discipline.
There is no magic default.
The out-of-the-box MAS framework helps, but you still decide the routing, schema, permissions, and error handling.
The talent shortage is real.
There is a shortage of people who understand MAS architecture, observability, and governance. Plan accordingly.
Frequently Asked Questions
Q: Is the “agent economy” real or propaganda?
A: Reliable estimates suggest that billions of AI agents will exist by 2028, with the use of distributed autonomous agents in enterprise systems increasing.
Q: Why can’t a single agent do everything?
A: Because complexity and tool multipliers dramatically increase the risk of error and loss of structure once the basic workflow is exceeded, industry experience shows that branching, validation, and role specialization are essential.
Q: Are Langgraph and PydanticAI the only frameworks?
A: No. There are other frameworks and approaches (e.g., CrewAI, AutoGen, platform-specific tools), but LangGraph and PydanticAI represent the two most practical options for Python-centric, graph-based, production-ready MAS.
Q: Do you need corporations to run MAS?
A: No — an open source MAS can be built using these tools. But the enterprise has brought observability, governance, and auditability to the production level.
Q: Is this a “plug and play” solution?
A: Not yet. MAS still requires architectural thinking, failure strategies, observability, and policies – just like any production system.





